SLURM scheduler
Contents
20. SLURM scheduler¶
The scheduler is needed to manage applications running on servers in a cluster. The applications can be submitted by different users on the cluster. The scheduler learns the requested by applications resources, checks if they are avaiable on the cluster nodes (servers), then despatches computational jobs to run on the nodes or places them in queue.
20.1. Why do we need SLURM?¶
Since we need to run benchmarks with many different parameters - nodes, osds, p_groups, it is easier to setup a batch submit script to run with various input files, one at a time, on the ceph cluster.
20.2. SLURM services¶
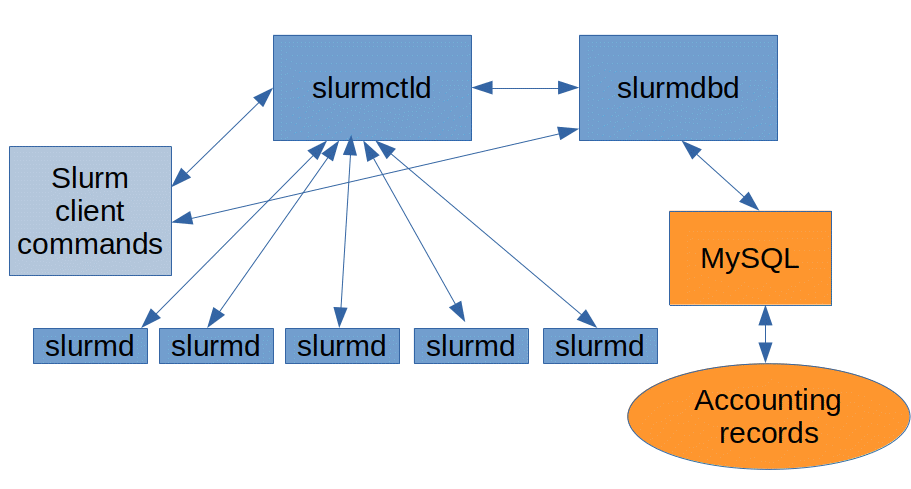
The scheduler includes the following services running on the management host:
slurmctld - the management daemon for job control and scheduling.
slurmdbd - the database daemon to communicate with MySQL db.
MySQL - the database with accounting configuration and completed job statistics.
On the compute nodes:
slurmd - to control running application on the node.
20.3. Installation on our system¶
Your lxsans container will be setup as the management host.
The ceph node will work as a compute node.
20.4. Steps:¶
20.4.1. Download ansible playbook from gitlabceph:¶
On the lxcans container, you need to download the ansible playbook for SLURM installation. For that, you get the public SSH key for user hostadm in file .ssh/rsa_id.pub:
cat .ssh/id_rsa.pub
Copy the key in the clipbioard.
Login to the gitlab, https://gitlabceph, as user hostadm. Navigate to your profile, select SSH key management, then paste the key into the box.
Now you should be able git clone the folder with the playbooks.
git clone git@gitlabceph:winlab/ceph.git
Step into the directory with the ansible playbook:
cd ceph/slurm-ansible/
Put the correct hosts in the following files:
hosts.ini: put the correct hostname of your node under [all_nodes].
roles/slurmd/files/slurm.conf: put the correct hostname for your lxcans container for parameter SlurmctldHost
roles/slurmd/files/slurm.conf: put the correct hostname of your node for NodeName in the line before the last, under “COMPUTE NODES.”
20.4.2. Run ansible playbook:¶
ansible-playbook playbook.yml
20.4.3. Restart services on lxcans container:¶
systemctl restart slurmdbd
systemctl restart slurmctld
20.4.4. Reboot the node¶
20.4.5. Restart services on the node:¶
systemctl restart slurmd
20.4.6. Check if the node is available for compute jobs:¶
sinfo -Nl
It should show the node in state IDLE.
20.5. Running bencmark jobs through SLURM¶
Download the benchmarks folder on lxcans from the gitlab:
cd
git clone git@gitlabceph:winlab/benchmarks.git
Copy mysql_scripts folder and the submit script, submit.sh into your home directory on lxcans:
cp -a benchmarks/mysql_scripts .
cp benchmarks/batch_slurm/submit.sh .
Copy the same folder and the submit script onto the computational node, for example node10:
cd
scp -r mysql_scripts node10:
scp submit.sh node10:
Launch the submit script, submit.sh, either from the lxcans container or the compute node:
sbatch submit.sh
To browse the running jobs, run command:
squeue
To list all the completed jobs, run:
sacct --format="JobID,JobName,State,Start,End"
For a specific job, for example with job_id=2:
sacct -j 2 --format="JobID,JobName,State,Start,End"
The stdout and stderror of the run will be saved in files slurm-%j.out and slurm-%j.err, where %j is the job_id of the run.
You can submit submit.sh several times, but only one job will run at a time on the node not to overload the I/O to Ceph.
20.6. Parameters in the submit script:¶
All the SLURM specific parameters begin with #SBATCH
–job-name= is for the job name to appear in the output of squeue or sacct commands
–output= is for the standard output file. The %j is substituted by the job_id of the run
–error= is for the standard error file.
–partition= name of the queue partition, winlab here.
–exclusive to reserve the node for the submitted job exclusively. The other submitted jobs will stay in queue until the job finishes.
the job is meant to run in the directory where the python scripts are placed, mysql_scripts.
The input file should be with the relative or the full path to the directory where it is located.