
High Performance Computing (part II: Message Passing Interface - MPI)
Contents
14. High Performance Computing (part II: Message Passing Interface - MPI)¶
What is MPI and how it works
MPI program structure
Environment management routines
How to compile and run MPI program
MPI point-to-point communications Blocking and non-blocking send/receive routines
MPI collective communication routines MPI_Reduce example
MPI lab exercises
14.1. Message Passing Interface (MPI)¶
Processes run on network distributed hosts and communicate by exchanging messages.
A community of communicating processes is called a Communicator. MPI_COMM_WORLD is the default.
Inside the communicator, each process is assigned its rank.
Each process runs the same code (SPMD model)
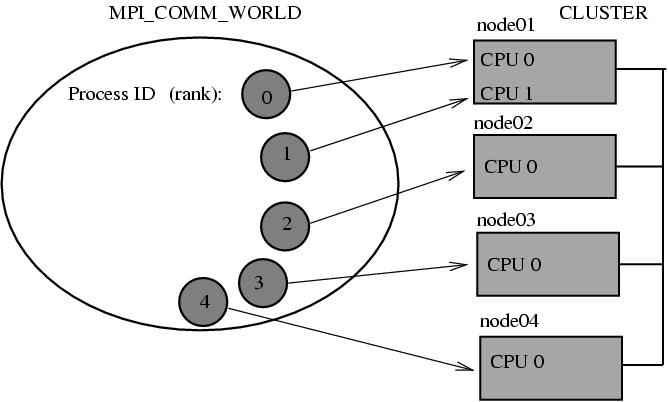
14.2. How an MPI Run Works¶
Every process gets a copy of the same executable: Single Program, Multiple Data (SPMD).
They all start executing it.
Each process works completely independently of the other processes, except when communicating.
Each looks at its own rank to determine which part of the problem to work on.
14.3. MPI is SPMD¶
To differentiate the roles of various processes running the same MPI code, you have to have if statements for the rank number. Often, the rank 0 process is referred as a master, and the other as a worker.
if (my_rank == 0) {
//do the master tasks
}
# similarly,
if (my_rank != 0) {
//do the worker tasks
}
14.4. General MPI program structure¶
MPI include header file #include "mpi.h"
Initialize MPI environment
Main coding and Message Passing calls
Terminate MPI environment
14.5. Major Environment Management Routines¶
MPI_Init (&argc, &argv)
MPI_Comm_size (comm, &size)
MPI_Comm_rank (comm, &rank)
MPI_Abort (comm, errorcode)
MPI_Get_processor_name (&name, &resultlength)
MPI_Finalize ()
14.6. MPI code template without send/receive.¶
Each process initializes the MPI environment, then prints out the number of processes, its rank, and the hostname
#include "mpi.h"
#include <stdio.h>
int main(int argc, char *argv[]) {
int numtasks, rank, len, rc;
char hostname[MPI_MAX_PROCESSOR_NAME];
// initialize MPI
MPI_Init(&argc, &argv);
// get MPI process rank, size, and processor name
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Get_processor_name(hostname, &len);
printf ("Number of tasks= %d My rank= %d Running on %s\n", numtasks, rank, hostname);
// Here we can do some computing and message passing ….
// done with MPI
MPI_Finalize();
}
14.7. MPI compilation and run examples¶
mpicc -o hello.x hello.c
To run the executable with 8 tasks on the same node:
mpirun -n 8 hello.x
To run the executable across 8 CPUs via SLURM on a cluster:
srun -n 8 hello.x
To run the executable across 2 nodes, 8 CPUs, and without a queue system:
mpirun -n 8 -hostfile nodes.txt hello.x
The hostfile, nodes.txt, defines CPU allocation, for example:
nodes.txt
node01 slots=4
node02 slots=4
14.8. MPI point-to-point communications¶
In two communicating MPI processes, one task is performing a send operation and the other task is performing a matching receive operation.
Blocking send/receive calls:
MPI_Send(&buffer, count, type, dest, tag, comm)
MPI_Recv(&buffer, count, type, source, tag, comm, status)
in MPI_Send
buffer – data elements, variables
count – the number of elements
type – MPI data type
dest - rank of the receiving process
in MPI_Recv
dest – the rank of receiving proc
source – rank of the sending proc
tag – int number, unique msg id
comm – communicator
14.9. MPI basic data types¶
MPI C/C++ data types |
C/C++ data types |
|---|---|
MPI_INT |
int |
MPI_LONG |
long int |
MPI_LONG_LONG |
long long int |
MPI_CHAR |
char |
MPI_UNSIGNED_CHAR |
unsigned char |
MPI_UNSIGNED |
unsigned int |
MPI_UNSIGNED_LONG |
unsigned long int |
MPI_UNSIGNED_LONG_LONG |
unsigned long long int |
MPI_FLOAT |
float |
MPI_DOUBLE |
double |
MPI_LONG_DOUBLE |
long double |
There are other data types. MPI also allows user defined data types.
14.10. Blocking send/receive example¶
Two processes with rank 0 and 1 initialize variables and the MPI environment, then the process of rank 0 sends a message to the rank 1 process
if (rank == 0) {
//send a message to proc 1
dest = 1;
MPI_Send(&outmsg, 9, MPI_CHAR, dest, tag, MPI_COMM_WORLD);
}
if (rank == 1) {
//receive a message from proc 0
source = 0;
MPI_Recv(&inmsg, 9, MPI_CHAR, source, tag, MPI_COMM_WORLD, &Stat);
}
14.11. Blocking MPI send/receive code example.¶
Each process initializes the MPI environment, then process with rank 0 sends “LCI_2019” to rank 1
#include "mpi.h"
#include <stdio.h>
int main(int argc, char *argv[]) {
int numRanks, rank, dest, source, rc, count, tag=222;
char inmsg[9], outmsg[9]="LCI_2019";
MPI_Status Stat;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD, &numRanks);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0) {
dest = 1;
MPI_Send(&outmsg, 9, MPI_CHAR, dest, tag, MPI_COMM_WORLD);
}
else if (rank == 1) {
source = 0;
MPI_Recv(&inmsg, 9, MPI_CHAR, source, tag, MPI_COMM_WORLD, &Stat);
printf("Rank %d Received %s from Rank %d \n", rank, inmsg, source);
}
MPI_Finalize();
14.12. Compiling and running the MPI blocking send/receive code¶
mpicc -o b_send_receive.x b_send_receive.c
mpirun -n 2 b_send_receive.x
output:
Rank 1 Received LCI_2019 from Rank 0
Task 1: Received 9 char(s) from task 0 with tag 222
14.13. MPI send/receive buffering¶
The MPI implementation (not the MPI standard) decides what happens to data between send/receive. Typically, a system buffer area is reserved to hold data in transit.
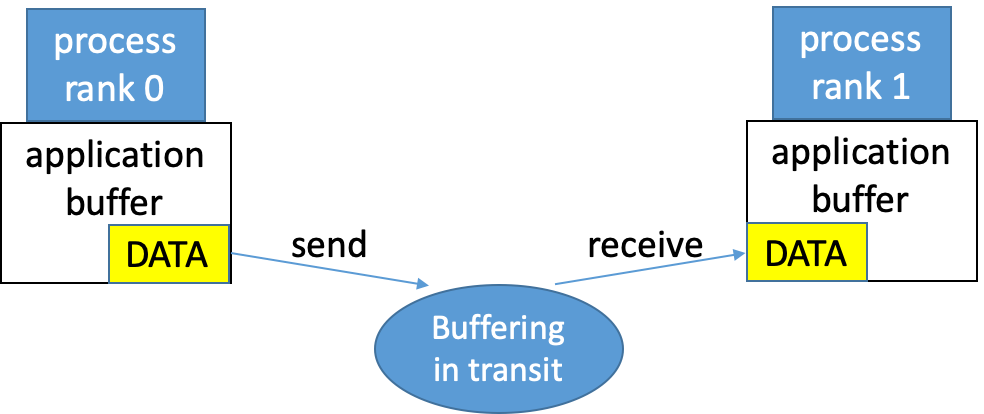
14.14. The blocking send/receive work flow¶
MPI_Send returns after it is safe to modify the send buffer.
MPI_Recv returns after the data has arrived in the receive buffer.

14.15. MPI non-blocking send/receive¶
The process of rank 0 sends a message to the rank 1 process via MPI_Isend, then continues running.
The rank 1 process may retrieve the data from the buffer later via MPI_Irecv.
Neither the send buffer can be updated, nor the receive buffer can be read until the processes make a synchronization call, MPI_wait.
if (rank == 0) {
//send a message to proc 1
dest = 1;
MPI_Isend(&outmsg, 9, MPI_CHAR, dest, tag, MPI_COMM_WORLD, &request);
}
if (rank == 1) {
//receive a message from proc 0
source = 0;
MPI_Irecv(&inmsg, 9, MPI_CHAR, source, tag, MPI_COMM_WORLD, &request);
}
MPI_wait(&request, &Stat);
14.16. The non-blocking send/receive work flow¶
The MPI_Isend returns right away, and the rank 0 process continues running. The rank 1 process may call MPI_Irecv later. The send buffer shouldn’t be updated and the receive buffer shouldn’t be read until MPI_Wait is called by the both tasks.

14.17. Non-Blocking MPI send/receive code example.¶
Each process initializes the MPI environment, then process with rank 0 sends “LCI_2019” to rank 1
#include "mpi.h"
#include <stdio.h>
int main(int argc, char *argv[]) {
int numRanks, rank, dest, source, rc, count, tag=222;
char inmsg[9], outmsg[9]="LCI_2019";
MPI_Status Stat; MPI_Request request = MPI_REQUEST_NULL;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD, &numRanks);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0) {
dest = 1;
MPI_Isend(&outmsg, 9, MPI_CHAR, dest, tag, MPI_COMM_WORLD, &request); }
else if (rank == 1) {
source = 0;
MPI_Irecv(&inmsg, 9, MPI_CHAR, source, tag, MPI_COMM_WORLD, &request);
}
MPI_Wait(&request, &Stat);
if (rank == 1) { printf("Rank %d Received %s from Rank %d \n", rank, inmsg, source); }
MPI_Finalize();
}
14.18. Compiling and running the MPI non-blocking send/receive code¶
mpicc -o nonb_send_receive.x nonb_send_receive.c
mpirun -n 2 nonb_send_receive.x
Rank 1 Received LCI_2019 from Rank 0
14.19. Send/Receive order and “fairness”¶
Author: Blaise Barney, Livermore Computing.
Order:
MPI guarantees that messages will not overtake each other.
If a sender sends two messages (Message 1 and Message 2) in succession to the same destination, and both match the same receive, the receive operation will receive Message 1 before Message 2.
If a receiver posts two receives (Receive 1 and Receive 2), in succession, and both are looking for the same message, Receive 1 will receive the message before Receive 2.
Order rules do not apply if there are multiple threads of the same process participating in the communication operations.
Fairness:
MPI does not guarantee fairness - it’s up to the programmer to prevent “operation starvation”.
Example: task 0 sends a message to task 2. However, task 1 sends a competing message that matches task 2’s receive. Only one of the sends will complete.
14.20. MPI collective communications¶
So far, we have reviewed the basic point-to-point MPI calls, involving pairs of processes.
For efficient programming, there are collective communication functions that involve all processes in the communicator,
MPI_COMM_WORLD.Some frequently used Collective communications routines:
MPI_Barrier– blocks execution until all the tasks reach itMPI_Bcast– sends a message to all MPI tasksMPI_Scatter– distributes data from one task to allMPI_Gather– collects data from all tasks into oneMPI_Allgather– concatenation of data to all tasksMPI_Reduce– reduction operation computed by all tasks
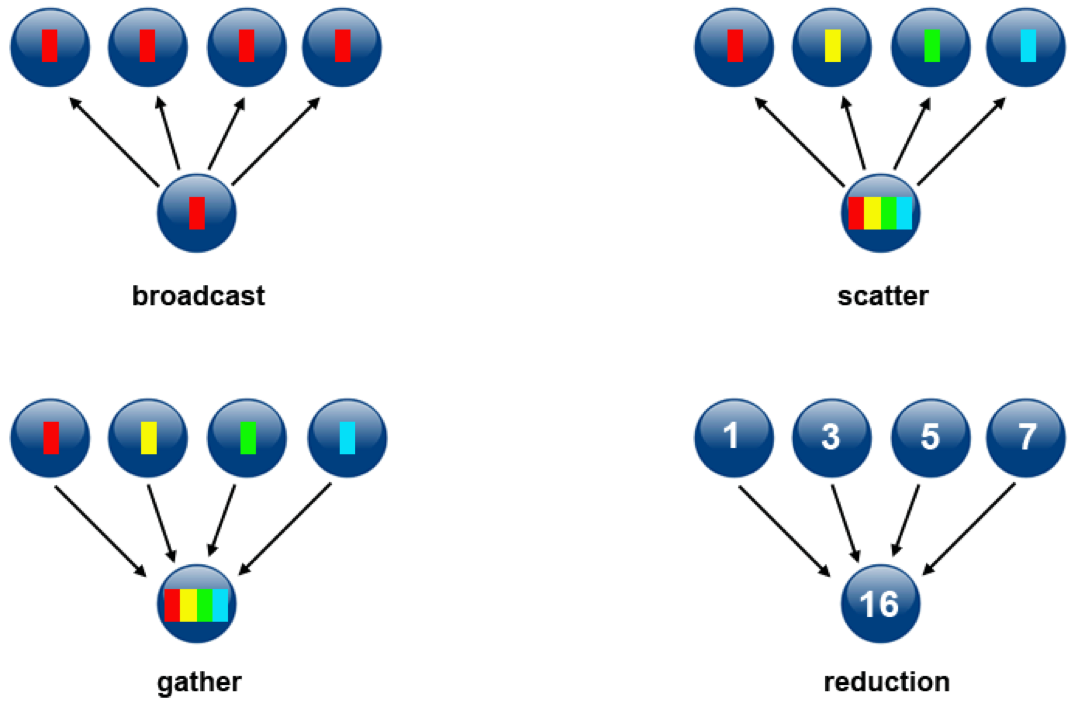
14.22. MPI_Reduce¶
Applies a reduction operation, op, on all processes (tasks) in the communicator, comm, and places the result in one task, root.
MPI_Reduce (&sendbuf,&recvbuf,count,datatype,op,root,comm)
14.23. Predefined MPI Reduction operations¶
MPI Reduction |
operation |
MPI C data types |
|---|---|---|
MPI_MAX |
maximum |
integer, float |
MPI_MIN |
minimum |
integer, float |
MPI_SUM |
sum |
integer, float |
MPI_PROD |
product |
integer, float |
MPI_LAND |
logical AND |
integer |
MPI_BAND |
bit-wise AND |
integer, MPI_BYTE |
MPI_LOR |
logical OR |
integer |
MPI_BOR |
bit-wise OR |
integer, MPI_BYTE |
MPI_LXOR |
logical XOR |
integer |
MPI_BXOR |
bit-wise XOR |
integer, MPI_BYTE |
MPI_MAXLOC |
max value and location |
float, double and long double |
MPI_MINLOC |
min value and location |
float, double and long double |
Users can also define their own reduction functions by using the MPI_Op_create routine.
14.24. Example: MPI_Reduce for a scalar product¶
Scalar product of two vectors, \(\vec{A}\) and \(\vec{B}\):
sum = \((\vec{A} \cdot \vec{B})\) = \(A_0 \cdot B_0 + A_1 \cdot B_1 + … + A_{n-1} \cdot B_{n-1} \)
Have each task to compute partial sums on a chunk of data, then
do MPI_Reduce on the partial sums and write the result to the task of rank 0:
int chunk = Array_Size/numprocs; //how many elements each process gets in the chunk
for (i=rank*chunk; i < (rank+1)*chunk; ++i)
part_sum += A[i] * B[i]; //Each process computes a partial sum on its chunk
MPI_Reduce(&part_sum, &sum, 1, MPI_FLOAT, MPI_SUM, 0, MPI_COMM_WORLD);
if (rank == 0) {
//print out the total sum
}
Each task has its full copy of arrays A[ ] and B[ ].
The Array_Size here is a multiple of variable chunk.
14.25. Compiling and running the MPI_Reduce code¶
mpicc -o mpi_reduce.x mpi_reduce.c
mpirun -n 4 mpi_reduce.x
14.26. Deploy a virtual cluster (Exericse)¶
Download VMs appliences, master and n01 into KVM directory:
cd KVM
wget http://capone.rutgers.edu/coursefiles/master.tgz
tar -zxvf master.tgz
rm master.tgz
wget http://capone.rutgers.edu/coursefiles/n01.tgz
tar -zxvf n01.tgz
rm n01.tgz
Deploy the VMs:
mv master.xml /etc/libvirt/qemu
mv n01.xml /etc/libvirt/qemu
virsh define /etc/libvirt/qemu/master.xml
virsh define /etc/libvirt/qemu/n01.xml
14.27. User accounts for MPI runs (Exercise)¶
Start master and n01 VMs:
virsh start master
virsh start n01
Login to master and check if user account edward exists:
virsh console master
sudo -s
id edward
Login as user edward to VM master and generate SSH RSA public/private keys for passwordless authentication. The passphrase should be empty:
su - edward
whoami
ssh-keygen -t rsa
cd .ssh
cp id_rsa.pub authorized_keys
As user edward, ssh to n01 from master The user should be able to access n01 without password.
14.28. Open MPI installation (Exercise)¶
Login to master VM:
virsh console master
On master, do MPI installation with apt-get
apt-get update
apt-get install openmpi-common openmpi-bin mpi-default-dev g++
Perform the same package installation on n01 VM.
14.29. MPI code compilation (Exercise)¶
Login to master as user edward.
Un-tar the source codes from the examples discussed, MPI.tgz, into a separate directory, MPI, as shown below:
wget http://linuxcourse.rutgers.edu/2024/html/lessons/HPC_2/MPI.tgz
mkdir MPI
cp MPI.tgz MPI; cd MPI
tar -zxvf MPI.tgz
The MPI codes can be compiled with command mpicc
mpicc -o hello.x hello.c
mpicc -o b_send_receive.x b_send_receive.c
mpicc -o nonb_send_receive.x nonb_send_receive.c
mpicc -o mpi_reduce.x mpi_reduce.c
Run hello.x code on 4 CPU slots:
mpirun -n 4 hello.x
Run the blocking send/receive code on 2 CPU slots:
mpirun -n 2 b_send_receive.x
Run the non-blocking send/receive code on 2 CPU slots:
mpirun -n 2 nonb_send_receive.x
Run the MPI Reduction code on 4 CPU slots:
mpirun -n 4 mpi_reduce.x
Run the MPI Reduction code on 8 CPU slots:
mpirun -n 8 mpi_reduce.x
14.30. MPI run on a cluster (Exercise)¶
To run MPI computations on a distributed system (a cluster), a shared file system, and a passwordless authentication between compute nodes are required. Our master and n01 VMS with NFS shared file system and a passwordless authentication can work as a computational cluster for MPI.
Create file nodes.txt with the following content by using nano editor:
nodes.txt
master slots=1
n01 slots=1
To test if MPI works across the two VMs, master and n01, run command uname -n via mpirun as follows:
mpirun -n 2 -hostfile nodes.txt uname -n
Similarly, run b_send_receive.x and nonb_send_receive.x:
mpirun -n 2 -hostfile nodes.txt b_send_receive.x
mpirun -n 2 -hostfile nodes.txt nonb_send_receive.x
Modify file nodes.txt by changing the number of CPU slots on the VMs:
nodes.txt
master slots=4
n01 slots=4
Run mpi_reduce.x on 8 CPUs across the two nodes:
mpirun -n 8 -hostfile nodes.txt mpi_reduce.x
14.31. Concluding remarks¶
Today, we have reviewed the basics of MPI programming, including an MPI code structure, point-to-point and collective communication routines, compilation and executable run with mpirun.
More advanced MPI routines and techniques, including user defined data types, multiple communicators, task topology can be found in the references.
Shortly, we’ll proceed with MPI lab exercises.